TODO: change this to reference (now it can't since the docusaurus can't parse the router)
see:
./src
进出口数据核验
起因是这张图:

由于该博指出了数据来源:海关总署,所以出于对数据准确性的兴趣,我也小小核验了一下。
天然砂出口数据
首先给出第一个结论,关于天然砂的判断完全错误,大陆并非没有向湾湾出口天然砂。
当然,你在海关总署找到这个品类确实不是一件容易得事情,这主要是因为这个网站做的相当糟糕,不支持模糊搜索,也不说明字段设计(尽管可能是国际通用)。
你首先得知道商品编码分四个类级,分别采用2、4、6、8位数字,意思就是每一级最多有100个子类(完全够用了),然后天然砂(如果我们搜索没错的话)是属于第二大类,编码为2505(此外,还有一个叫“其他天然砂”的第三大类,编码为250590)。
出口如下,平均每个月100w人民币左右:
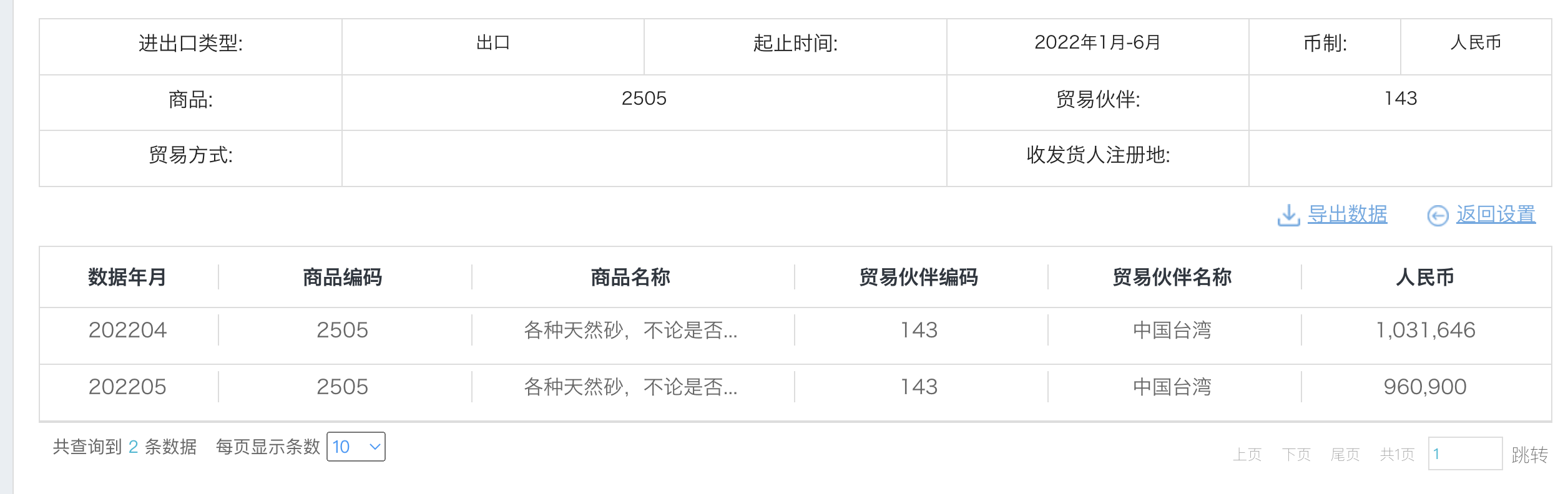
而且还没有1-3月数据,所以再看一下去年的数据:
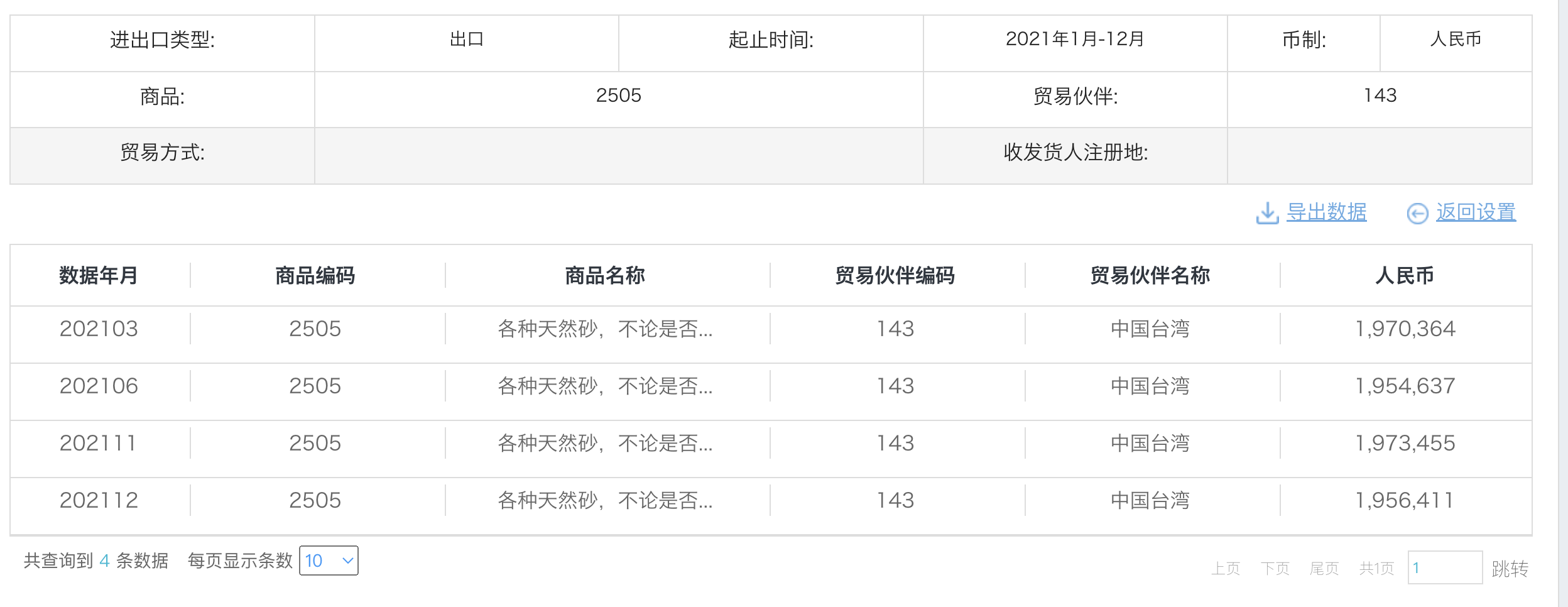
基本是一年1kw左右。
冰鲜带鱼进口数据
图中提到的冰鲜带鱼其实应该是其子类“冰鲜白带鱼”:
但不管了,我们允许向上估计,同样的流程,我们搜索出比较对标的编码是 03028910,03038910 :
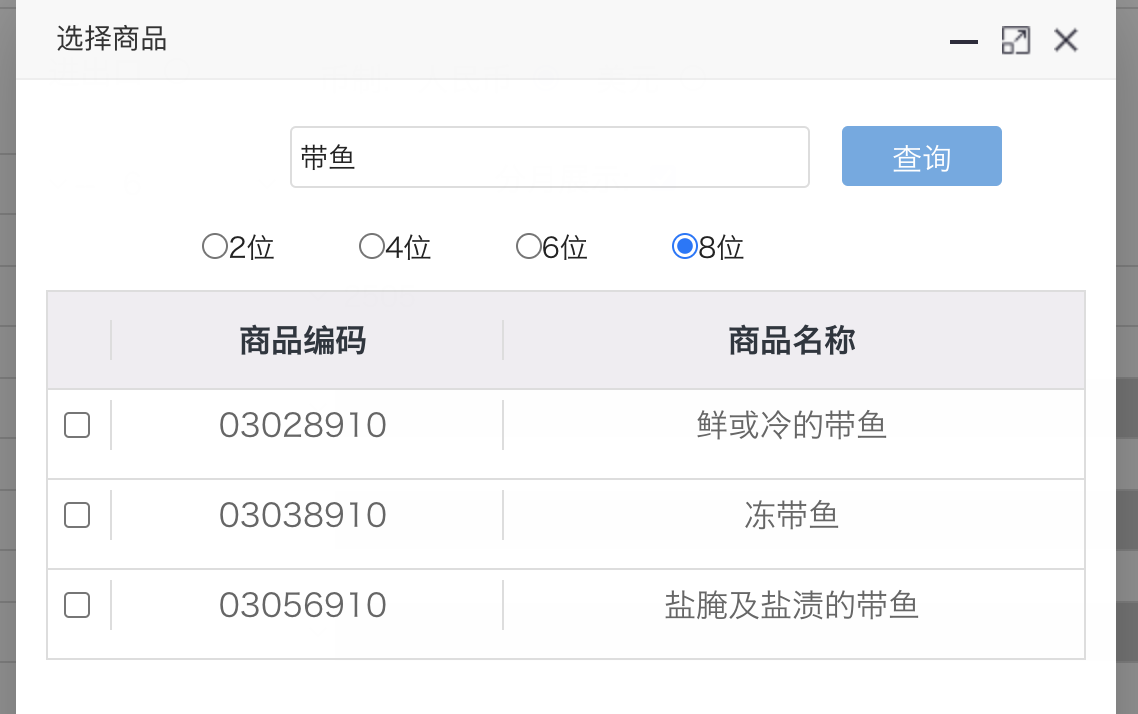
结果如下:
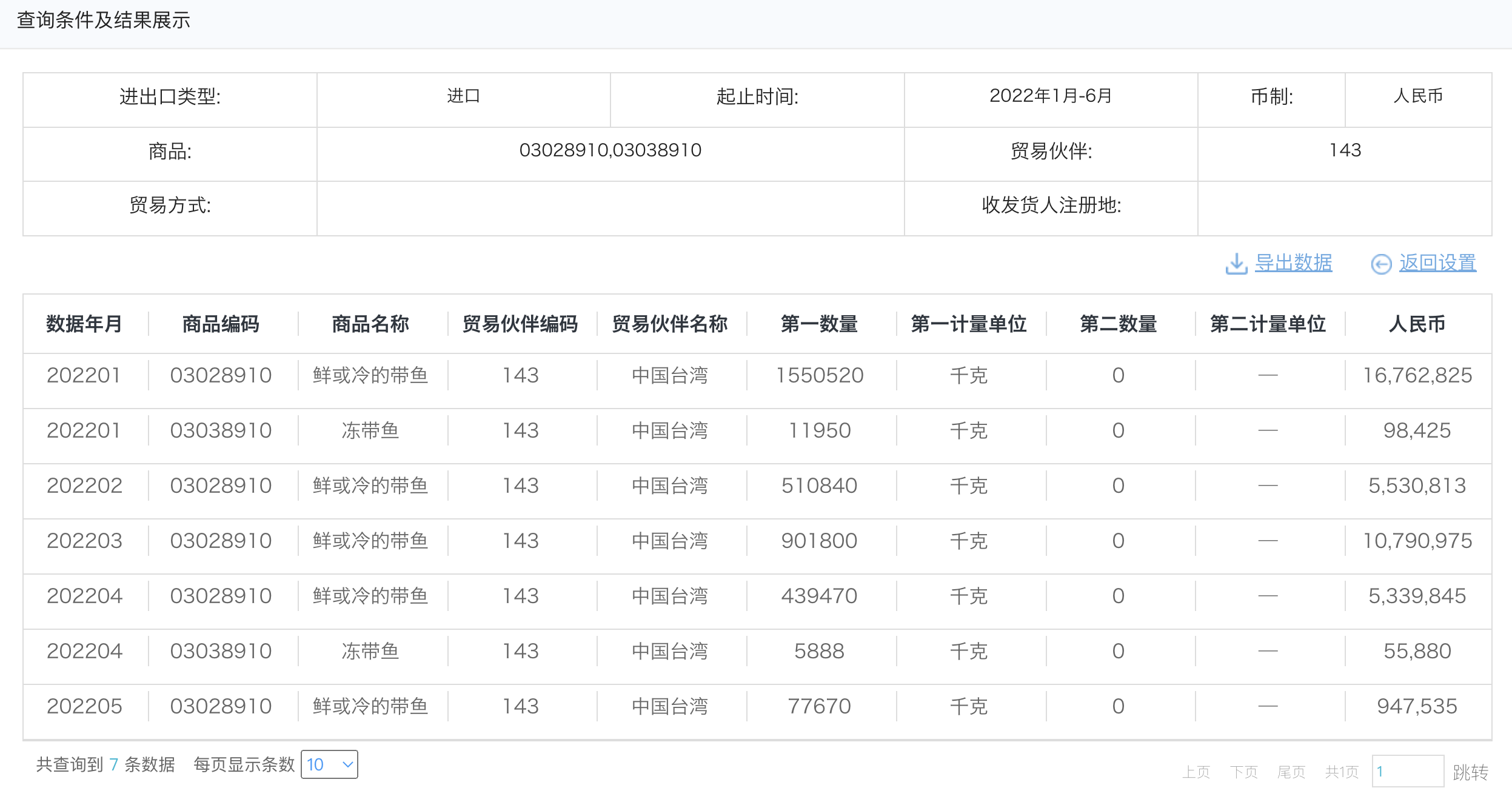
大概每个月1600w左右,1-6月总值确实与其计算的3937w接近。

冻竹荚鱼进口数据
同上处理,得到的数据也接近。
结论
尽管天然砂出口湾湾的量并不大,还不及这几条鱼,但显然,互联网的信息传播依然很经不起推敲。
但如我和大家讨论的,我更关心天然砂对湾湾的产能影响:

因为我找到了某个媒体新闻,说湾湾依赖大陆的天然砂达90%(2021年):
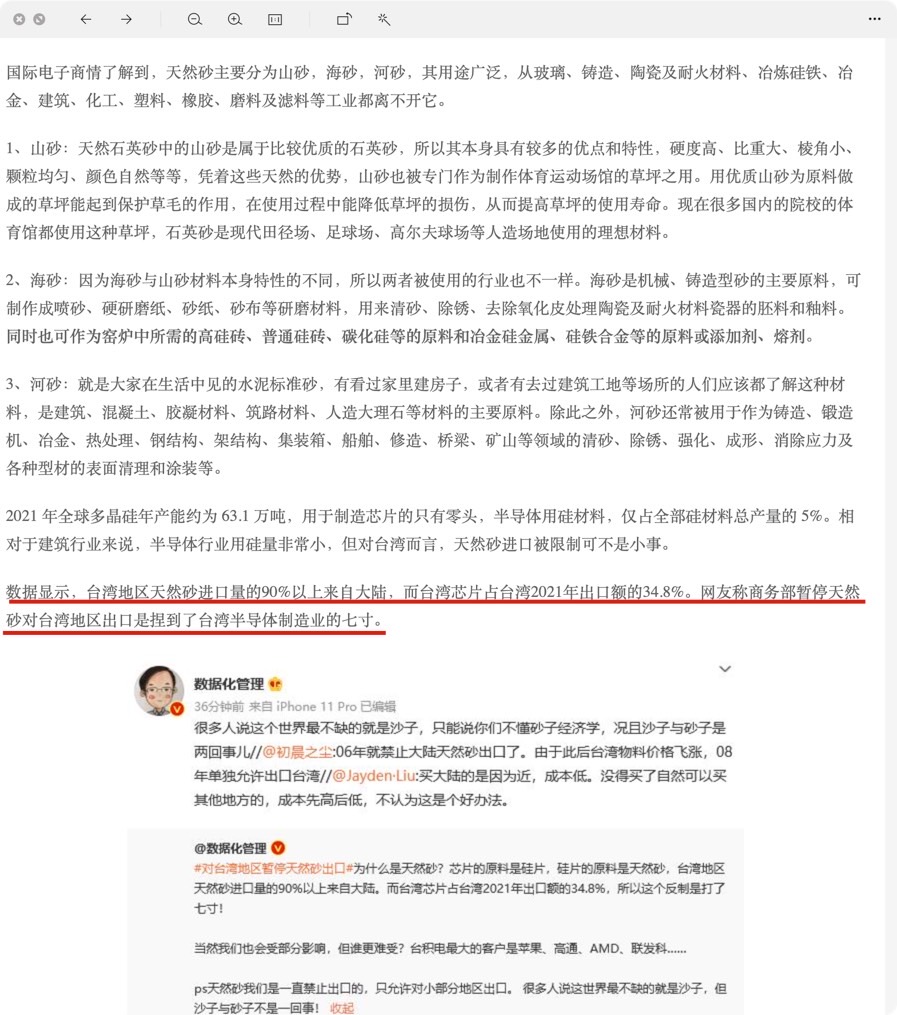
并称之为“捏到了台湾半导体制造业的七寸”。
那是否果真如此呢?
台湾天然砂进口分析
与大陆系统对比分析
这一次,我们需要用到台湾的海关总署数据了。
这个平台做的就远比国内的海关总署数据用心多了,体验好非常多,前面那个就属实摆烂(国内政企saas的通病,故意让你用的不爽)。
不过除此使用,则会有意外的感受,那就是年份是从92到111,我脑子迅速地过了一下,2022-111=1911,好家伙,原来是以民国元年为第一年计算的……
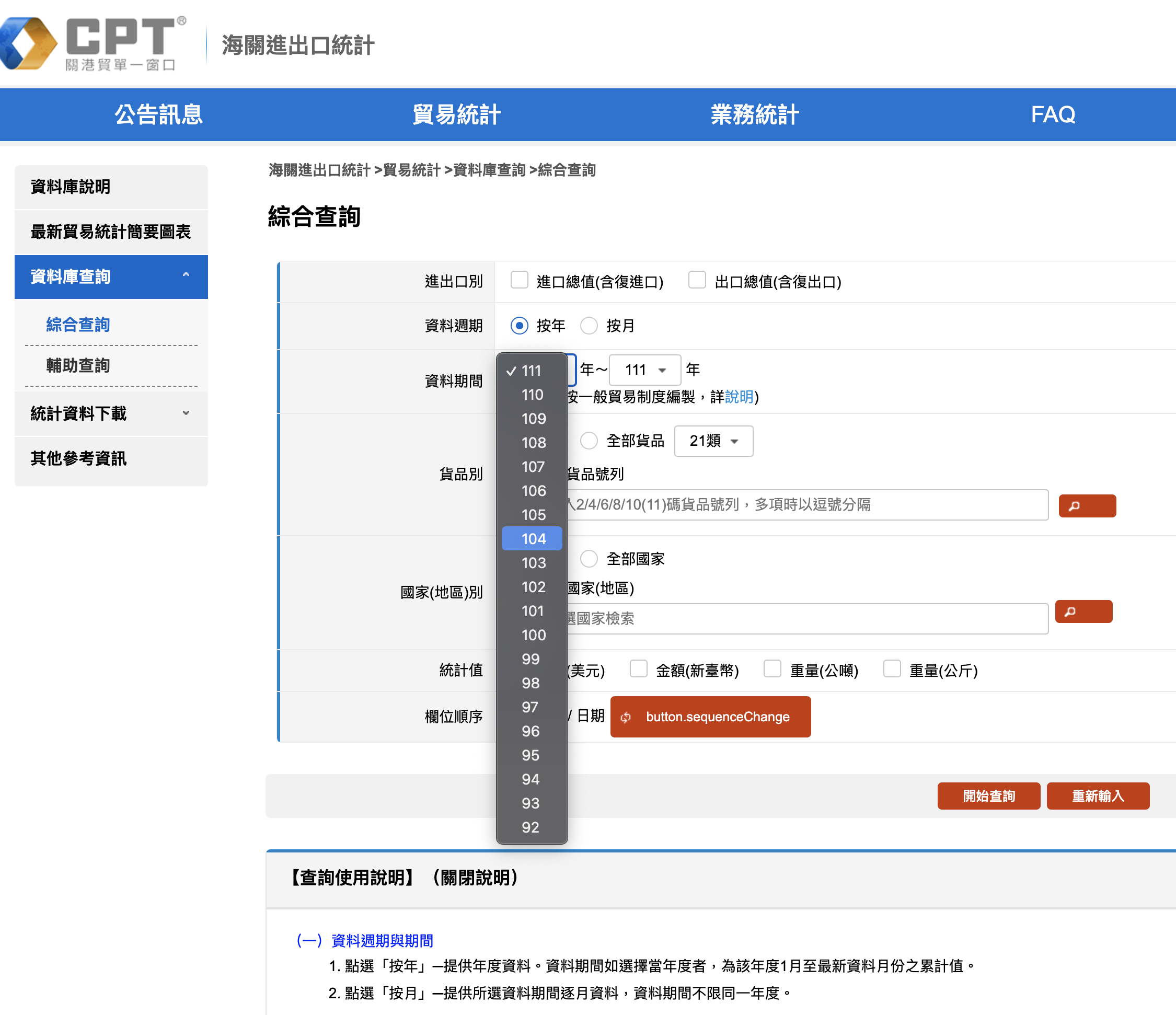
不管这个啦,继续我们的研究。
刚刚我们说了编码是通用的,天然砂的编码是2505,所以我们直接输就可以。
可以看到,湾湾的软件就可以对出口和进口同时分类显示,这才是正常的设计:

然后只有美元和新台币两种计价单位,为了核算,我们一律使用美元,然后再把之前的国内海关署的台湾出口天然砂数据拉一下对比看看:
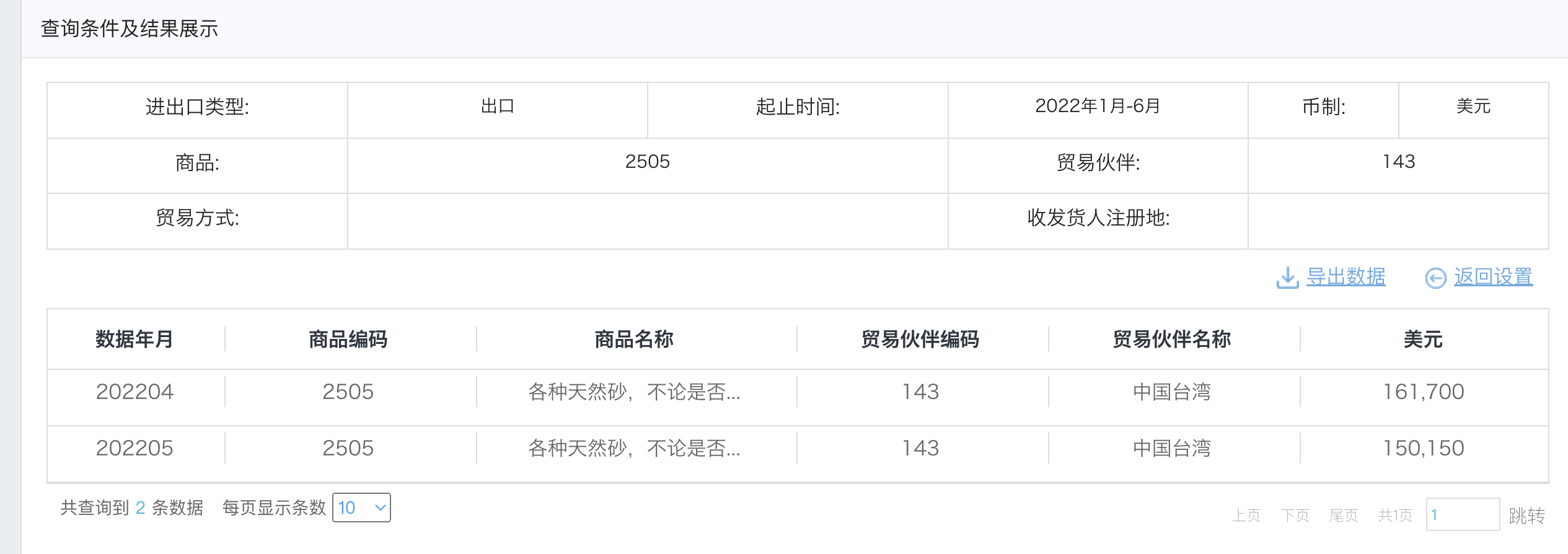
可以看到,国内显示对湾出口天然砂4月有16.17万美元,5月有15.015万美元,而湾湾显示对大陆进口天然砂个月有34.3万美元,5月有30.7万美元。
对不上。
不过注意,湾湾表示,这些字段是包含复进口的,所以多一点也许也可以理解。
不过令我最不解的是,国内只有个别月有数据,这显然是不正常的。
所以,假如湾湾是客观正确的,那么国内数据系统没有错的话,那就是人为降低了数据量。
那国内为啥会少报出口量呢,好像也没有道理,所以权当是数据系统错误吧。
反正那个系统(除了验证码都是准确的之外),你也不能指望能准到哪里去。
大陆占比分析
接下来研究湾湾进口天然砂的大陆占比,是否果真达到了90%。
数据上,由于湾湾的海关数据系统做的非常好,所以我们很方便地能拿到湾湾从民国92年(2003)到111年(2022)从世界各国进口天然砂的数据:
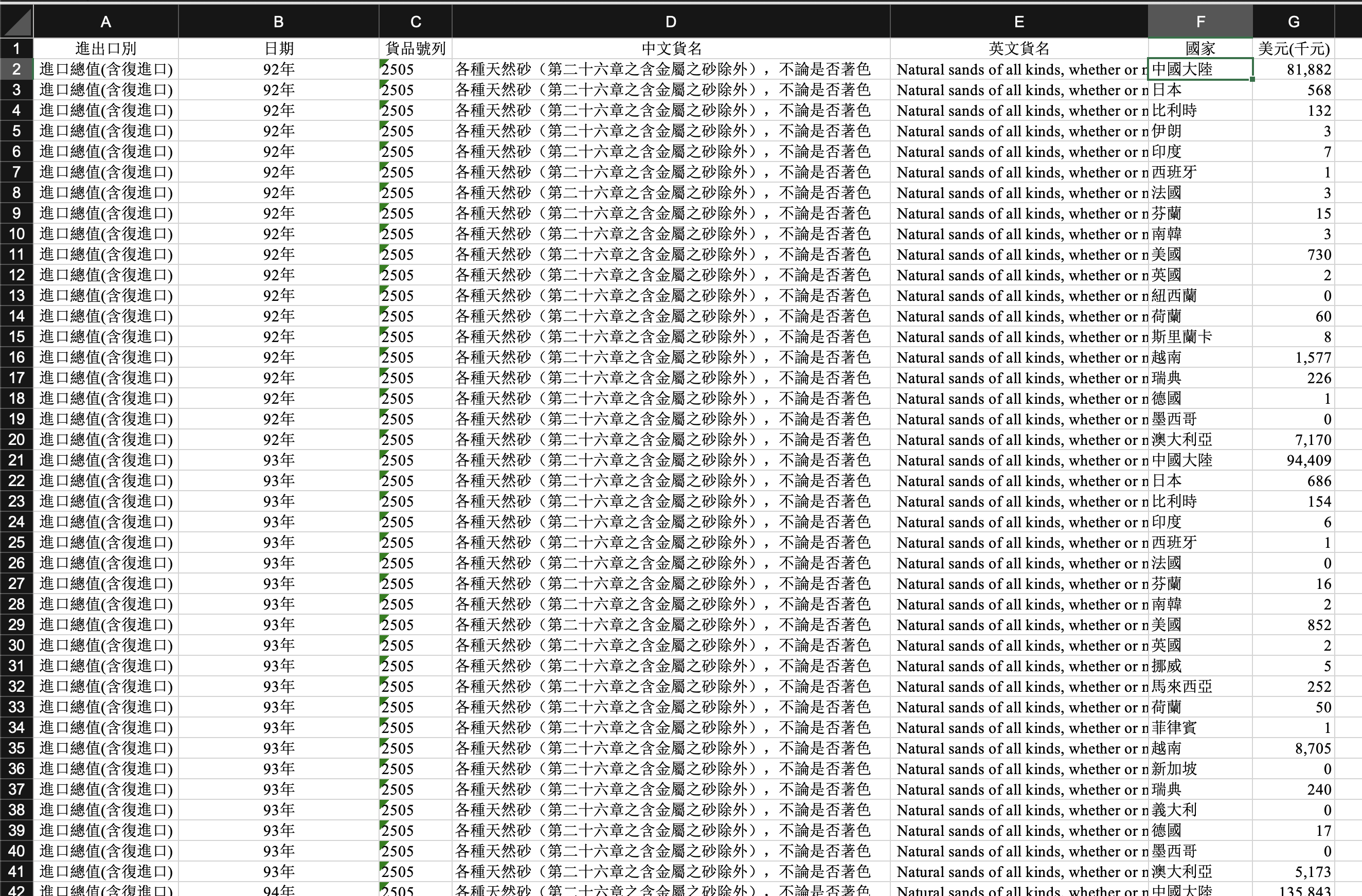
然后我们只需要按年分组,分别求得中国进口金额、全球总计进口金额与其两者的比值,最终得到结果如下:
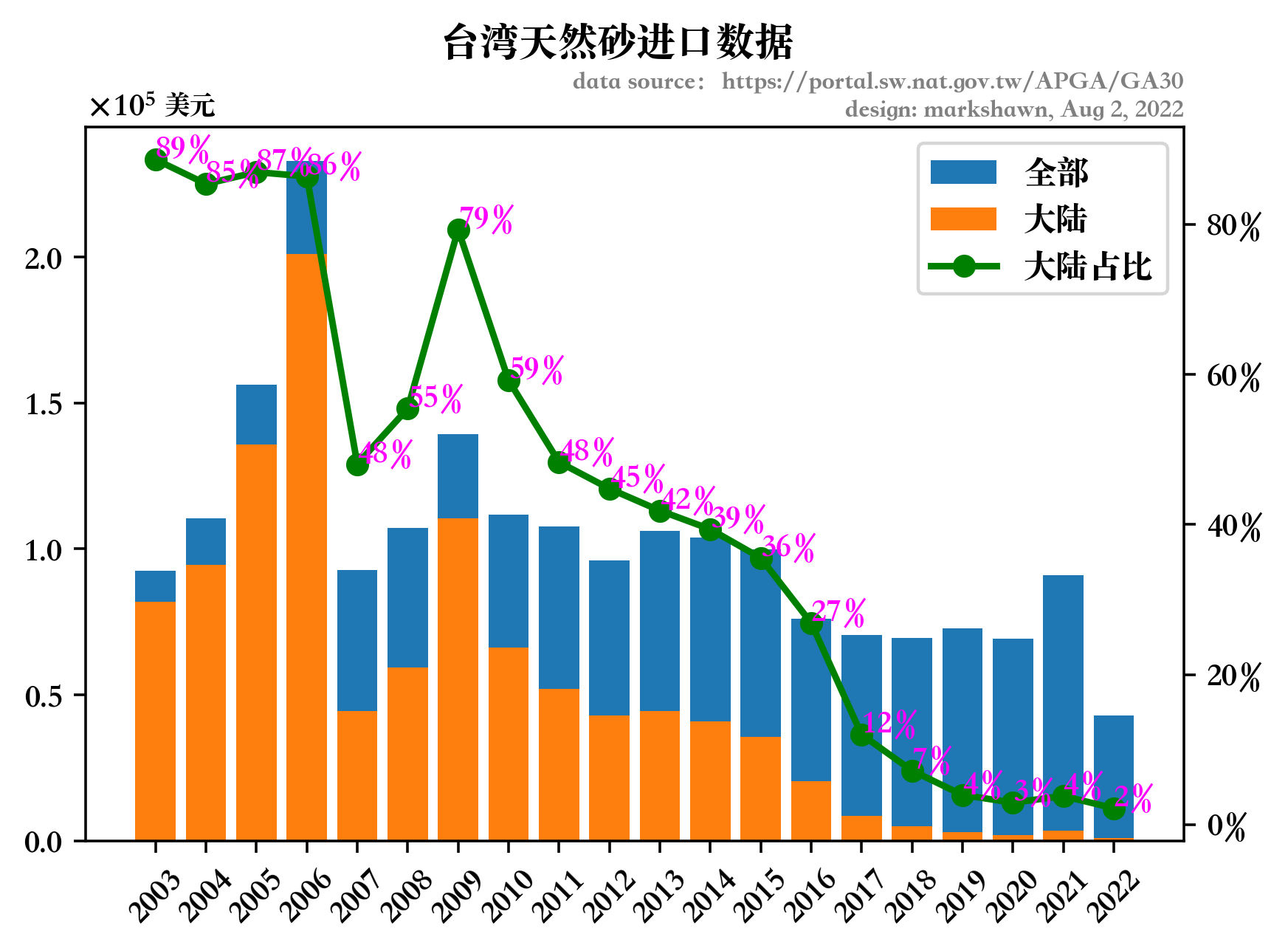
很遗憾的是,06年及以前,台湾对大陆的天然砂确实依赖程度高达90%,但是09年之后就断崖式下跌,19年之后已完全在5%以下……
无话可说。
台湾历年进出口数据国别分析
最后,趁着这个机会,研究一下台湾对各国进出口的情况。
由于年份和国家众多,想展示趋势并不太容易,所以敲定的方案就是选择十个典型国家,其他的用“others”去合计。
而这十个典型的国家,基于2021年湾湾进口金额前十的国家,它们依次是:
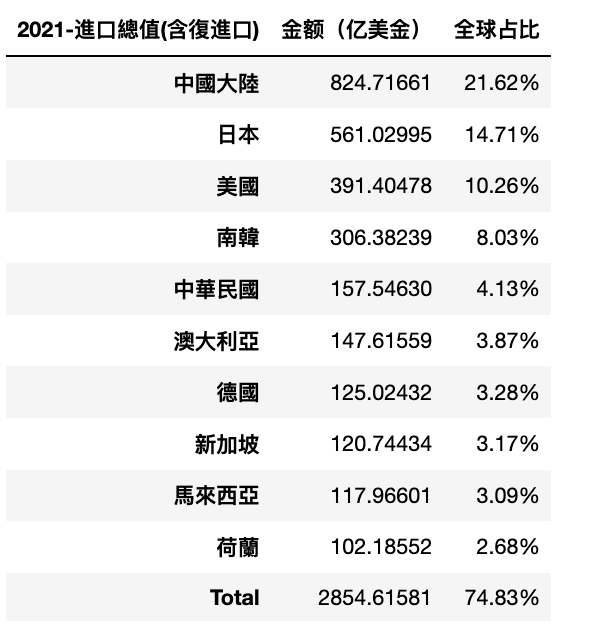
值得注意的是,前十的总和也只有 75%,说明湾湾的多边合作做的还是不错的。
最后直接上图吧:
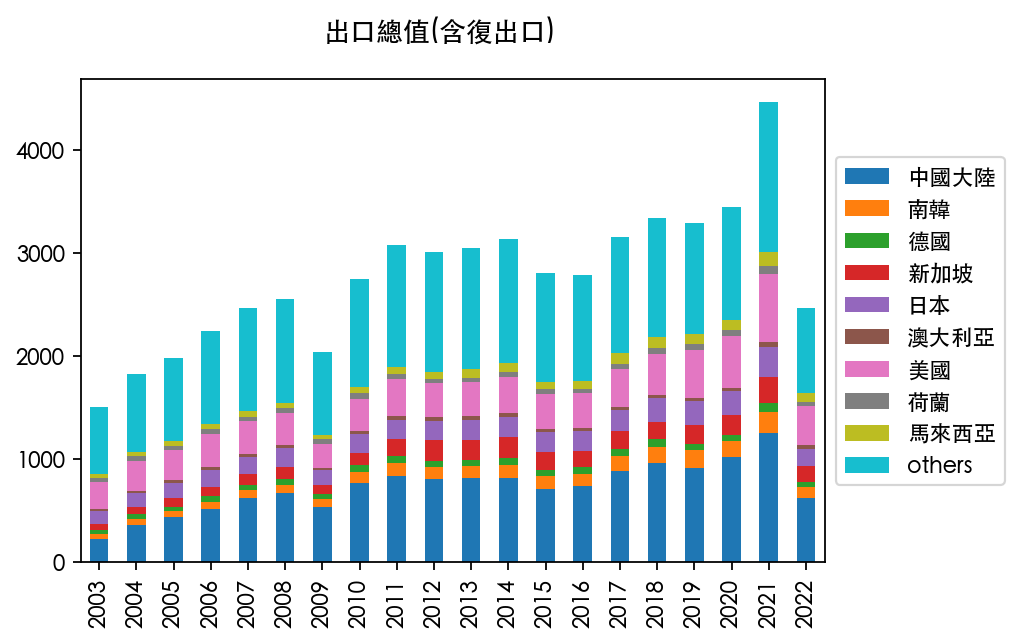
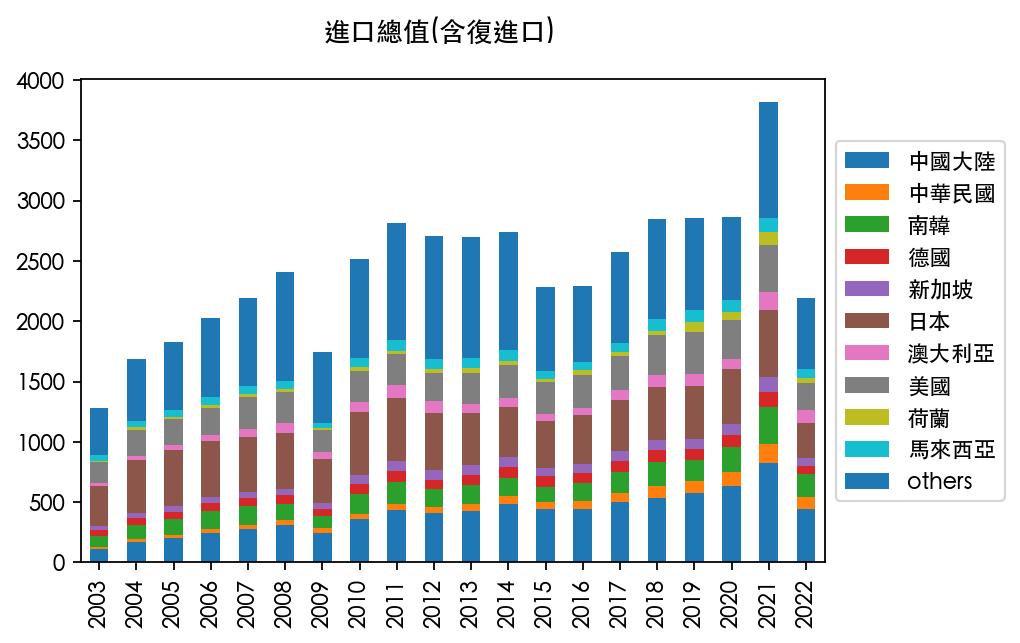
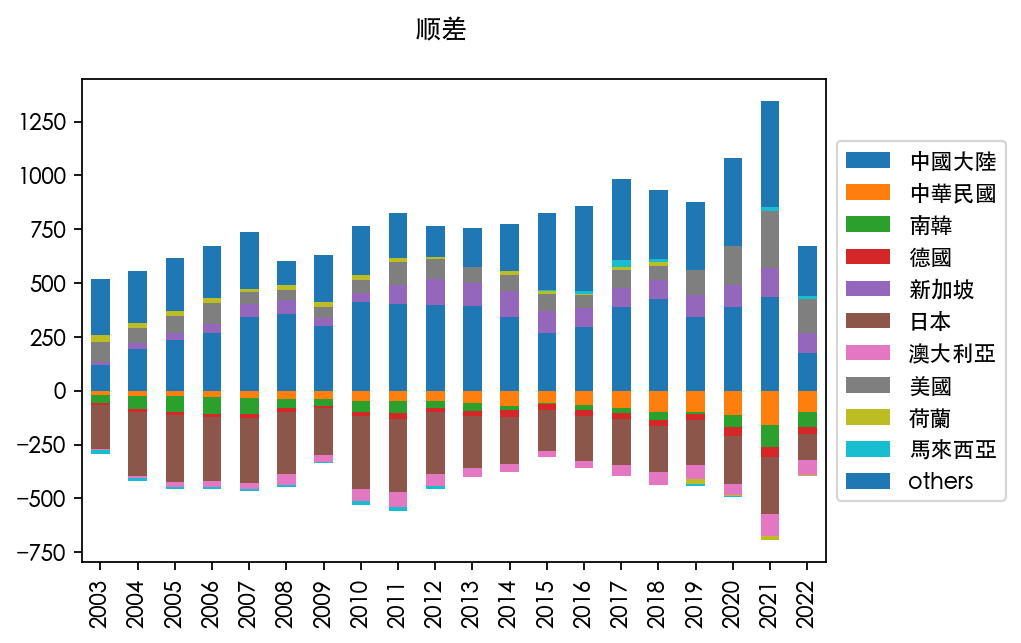
以上!
代码
代码一:台湾天然砂进口分析
import re
import pandas as pd
import matplotlib.pyplot as plt
from mpl_toolkits.axes_grid1 import host_subplot
from matplotlib.ticker import ScalarFormatter, PercentFormatter
plt.rcParams["figure.dpi"] = 320
plt.rcParams['font.sans-serif']=['Heiti TC', 'Songti SC']
### step 1. data fetch
# 台湾海关数据查询网址: https://portal.sw.nat.gov.tw/APGA/GA30
# 参数设置:货品(天然砂):2505
df = pd.read_excel("~/Downloads/綜合查詢_20220803143014.xls")
### step 2. data wash
def china_with_world(df: pd.DataFrame):
china = float(df[df['國家'] == '中國大陸']['美元(千元)'])
total = df['美元(千元)'].sum()
pct = china / total
return pd.Series({
"total": total,
'china': china,
'pct': pct
})
df['year'] = df['日期'].apply(lambda x: int(re.search(r'\d+', x).group()) + 1912 - 1)
df2 = df.groupby(['year']).apply(china_with_world).reset_index()
display(df2)
### step 3. data visualization
# scientific formatter, ref: https://atmamani.github.io/cheatsheets/matplotlib/matplotlib_2/#Numbers-on-axes-in-scientific-notation
formatter = ScalarFormatter(useMathText=True)
formatter.set_powerlimits((0, 1)) # https://matplotlib.org/3.4.3/api/ticker_api.html#matplotlib.ticker.ScalarFormatter.set_powerlimits
# two kinds draw from dataframe: https://www.statology.org/matplotlib-two-y-axes/
ax1 = host_subplot(111)
ax1.yaxis.set_major_formatter(formatter)
ax2 = ax1.twinx()
ax2.yaxis.set_major_formatter(PercentFormatter(1))
index = df2.year.astype(str)
ax1.bar(index, df2.total, label='全部')
ax1.bar(index, df2.china, label='大陆')
ax2.plot(index, df2.pct, 'g-o', linewidth=2, label='大陆占比')
for i,j in zip(index, df2.pct):
ax2.annotate(f'{j*100:.0f}%',xy=(i,j), color='magenta')
plt.figtext(.5,.99,'台湾天然砂进口数据', size=12, ha='center', va="top")
plt.figtext(.9,.92,'data source:https://portal.sw.nat.gov.tw/APGA/GA30', size=8, ha='right', color='gray', style='italic')
plt.figtext(.9,.89,'design: markshawn, Aug 2, 2022', size=8, ha='right', color='gray', style='italic')
plt.figtext(.18,.895,'美元', size=8, style='italic')
plt.legend()
plt.xticks(rotation = 45); # Rotates X-Axis Ticks by 45-degrees
代码二:台湾历年进出口分析
# 数据:https://portal.sw.nat.gov.tw/APGA/GA30_LIST
def preprocess(fp) -> pd.DataFrame:
df = pd.read_excel(fp)
df = df.rename(columns = {
'進出口別': 'io',
'日期': 'year',
'國家': 'country',
'貨品號列': 'good_kind_id',
'中文貨名': 'good_kind_name_cn',
'英文貨名': 'good_kind_name_en',
'美元(千元)': 'amount_k'
})
df['year'] = df.year.apply(lambda x: int(re.search('\d+', x).group()) + 1912 - 1)
return df
def addTotalRow(df: pd.DataFrame):
totalRow = df.sum(numeric_only=True).to_frame(name='Total').T
return pd.concat([df, totalRow])
def calcDir(df: pd.DataFrame):
s = df.groupby('io').sum()['amount_k']
s['顺差'] = s.get('出口總值(含復出口)', 0) - s.get('進口總值(含復進口)', 0)
return s
def getTopCountries(df, io="進口總值(含復進口)", year=2021, N=10):
dff = df.query(f'io=="{io}" and year=={year}')
dfs = dff.sort_values('amount_k', ascending=False)
dfs.set_index('country', inplace=True)
total = dfs.amount_k.sum()
print('total: ', total)
dfs['pct'] = dfs.amount_k / total
return dfs[:N]
def squashCountries(df: pd.DataFrame):
cur = df.query(f'country in {topCountries}')
sumOthers = df.query(f'country not in {topCountries}')['amount_k'].sum()
newRows = pd.DataFrame([{"country": "others", "amount_k": sumOthers, 'io': df['io'].iloc[0]}])
result = pd.concat([cur, newRows])
return result
def handleYear(df):
return squashCountries(df).set_index('country')['amount_k']
def plotTrend(df, name=None):
df.plot(kind='bar', stacked=True);
plt.legend(bbox_to_anchor =(1, 0.5), loc='center left');
plt.xlabel(None)
if name:
plt.suptitle(name)
plt.show();
def handleIO(df):
df2 = df.groupby('year')\
.apply(handleYear) / 1e8 * 1e3
plotTrend(df2, df.name)
def showTop(dfTopCountries):
x = addTotalRow(dfTopCountries)
x.columns.name = str(int(x.year.iloc[0])) + "-" + x.io.iloc[0]
x.drop(columns=['year', 'io'], inplace=True)
x['金额(亿美金)'] = x.amount_k / 1e8 * 1e3
x['全球占比'] = x.pct.apply(lambda x: f"{x*100:.2f}%")
display(x.drop(columns=['amount_k', 'pct']))
df = preprocess('/Users/mark/Downloads/綜合查詢_20220803190515.xls')
df2 = df.groupby(['country', 'year']).apply(calcDir).reset_index()
dfTopCountries = getTopCountries(df2)
showTop(dfTopCountries)
topCountries = dfTopCountries.index.to_list()
df2\
.groupby('io')\
.apply(handleIO)